
Digital Assesment & Data Infrastructure deep dive per la valorizzazione del dato
Analisi di processi, applicazioni e infrastruttura dati per l’identificazione di aree di miglioramento applicative e l’evoluzione della data platform
- Cliente: azienda italiana leader in ambito Fresh Food Online Retail
- Servizio dD: Digital Assessment & IT Evolution Roadmap; Data Strategy
ESIGENZA
L’azienda cliente è leader in Italia nell’ambito del fresh food online retail. Serve sul territorio nazionale più di 100.000 clienti con un alto livello di servizio, caratterizzato da consegne entro le 24 ore dall’emissione dell’ordine. Vista la peculiarità del mercato e del modello operativo, l’organizzazione ha spesso fatto ricorso negli anni a sviluppi interni e soluzioni custom per coprire le esigenze di supporto applicativo richieste dal Business. In tal senso, si è resa necessaria un’analisi volta a verificare la situazione in termini di processi e strumenti digitali, per delineare e identificare le principali aree non coperte o che necessitassero di miglioramento. In aggiunta a ciò, trattandosi di un business con molteplici punti di contatto con il cliente e quindi di fonti dati, è emersa la necessità di far chiarezza rispetto alla Data Infrastructure/Pipeline, al fine di identificarne punti di debolezza e attivare un’opportuna ricognizione di soluzioni mercato per valutare le opportunità di evoluzione ed introduzione di nuove tecnologie.
OBIETTIVO DEL PROGETTO
Le priorità strategiche dell’azienda e le esigenze di business sono state utilizzate per indirizzare le attività di assessment relative ai seguenti ambiti:
- Verifica della copertura del supporto applicativo ai processi
- Mappatura delle applicazioni in uso e valutazione della coerenza del portafoglio applicativo
- Mappatura e valutazione delle componenti architetturali della Data Infrastructure
SOLUZIONE PROGETTUALE E RISULTATI
Come anticipato, questo tipo di progettualità si focalizza su 2 elementi principali:
1.Processi e supporto applicativo
2.Data Platform Infrastructure
Per analizzare opportunamente questi aspetti, sono stati intervistati dapprima gli attori di Business (Process Owner) per l’approfondimento di ciascun processo facente parte della catena del valore sotto illustrata. È stato svolto in seguito un passaggio con l’IT per raccogliere maggiori dettagli sulle applicazioni analizzate in sede di intervista. Per quanto riguarda il secondo ambito, ci si è focalizzati ad effettuare approfondimenti esclusivamente con il team dati dell’organizzazione.

Assessment dei processi aziendali e del supporto applicativo con il Business
Per quanto riguarda l’approfondimento legato ai processi in scope, sono stati intervistati Process Owner ed utenti, ponendo particolare attenzione ai sistemi utilizzati all’interno di ciascun processo, ai punti di attenzione applicativi e alle segnalazioni fornite dagli utenti rispetto ad aree di miglioramento funzionali da indirizzare. In aggiunta a ciò, sono state rilevate e dedotte dal team di progetto doDigital ulteriori spazi di miglioramento figli di limiti funzionali delle applicazioni o finalizzati all’implementazione di evoluzioni aggiuntive. Le mappature risultanti hanno permesso di analizzare la copertura funzionale dei sistemi e la soddisfazione degli utenti nel rispetto delle attività da svolgere a livello operativo.
In aggiunta a ciò, è stata svolta un’analisi di dettaglio particolare su:
- Uno specifico sistema custom sviluppato internamente dall’organizzazione, identificando i diversi microservizi compresi. Tali analisi sono state realizzate con l’intento di fornire una panoramica di dettaglio sull’applicazione nell’ottica di un nuovo sviluppo/ridisegno;
- Criticità dei processi aziendali in termini di numerosità di attori coinvolti, potenziali bottleneck, margini di ottimizzazione potenziali e livello di standardizzazione, con l’obiettivo di definire i processi prioritari su cui intervenire.

Data Platform Infrastructure deep dive
Per quanto riguarda l’approfondimento legato alla Data Platform, sono state svolte delle sessioni verticali con le figure appartenenti al team dati dell’azienda cliente, costituito da Data Engineer, Data Scientist e Data Analyst. In queste sessioni, ci si è serviti di strumenti visuali funzionali a tracciare assieme agli intervistati il percorso che i dati aziendali percorrevano a partire dalla fonte (Data Sources) fino ad arrivare ai sistemi di Data Visualisation/Bi o tool utilizzati dalla figura di Data Scientist per implementare modelli di Machine Learning (Analysis & Output). A titolo di esempio, alimentando un modello previsionale che consentisse di prevedere gli ordini di prodotti freschi da effettuare in un determinato momento per il rifornimento dello stock.
L’analisi ha permesso di disegnare completamente il Data Lineage, in particolare evidenziando le componenti e lo stack tecnologico presente, dove fosse possibile fruire del dato in tempo reale e dove in modalità batch, le trasformazioni effettuate. All’interno di questa mappatura, sono state evidenziate aree di miglioramento quali il disallineamento tra determinati job batch, la mancata valorizzazione di determinati campi, errori nelle query.

Utilizzando come input l’analisi svolta, è stata portata avanti un ricognizione di mercato volta ad acquisire informazioni sui tool che potessero essere introdotti (in sostituzione e non) all’attuale stack tecnologico per indirizzare i punti di miglioramento identificati. La ricerca ha portato all’identificazione di due principali cluster di soluzioni potenzialmente utili per lo scenario in esame:
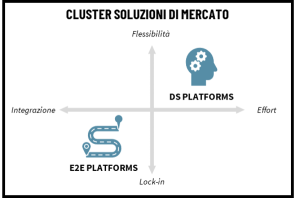
- End-to-End Platform: piattaforme in grado di gestire il dato a partire dall’ingestion fino ad arrivare alla messa a disposizione del business. Questo tipo di piattaforme consentono di mantenere alto il presidio sul dato in tutto il ciclo di vita, ma vincolano le organizzazioni ad una determinata scelta tecnologica (lock-in);
- Data Science Platform: piattaforme squisitamente focalizzate nel fornire ai Data Scientist gli strumenti per mettere a valore i dati in un ambiente disegnato per l’implementazione di algoritmi di AI e Machine Learning. Se da un lato questo tipo di soluzioni garantiscono una maggiore flessibilità, dall’altro lato rendono necessaria la presenza di altri tool per le attività di ingestion e trasport, aumentando l’effort di integrazione e gestione da parte del team IT interno.
Sulla base di questi due principali cluster e delle soluzioni identificate, caratterizzate da diversi livelli di copertura, sono stati redatti una serie di scenari evolutivi della Data Platform che partissero dallo stack tecnologico esistente, senza intaccarlo eccessivamente o sostituirlo, ma anche piani di evoluzione che invece contemplassero questa opportunità, illustrandone rispettivi costi, opportunità e rischi.
Risultati ottenuti
L’iniziativa portata avanti sui due ambiti analizzati precedentemente ha portato evidenze all’organizzazione cliente rispetto a:
1.Principali aspetti da indirizzare per ciascun processo al fine di ottimizzarlo e migliorarlo in termini di flusso di attività, supporto applicativo e funzionale;
2.Scenari di evoluzione della propria data pipeline, con relativi opportunità e rischi connessi a flessibilità, livello di integrazione, effort manutentivo delle soluzioni di mercato a disposizione.
In questo modo, sono stati forniti tutti gli elementi necessari per poter avanzare ipotesi sulle iniziative da portare avanti per il miglioramento dei propri processi e la direzione da intraprendere per migliorare la strategia di valorizzazione del patrimonio informativo aziendale.



